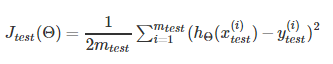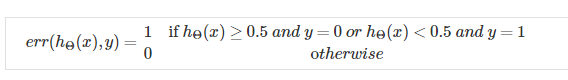[W6]机器学习应用建议
采取什么措施来进一步优化
主要有五种措施
1.获取更多训练样本
2.尝试使用更小规模的特称
3.尝试增加特征
4.尝试使用多项式特征
5.增加或者减小正则参数λ
评估假设
我们如何评估一个已经做出的假设是否合理呢?也许我们的假设在训练集合上面有较好的表现,但是对于其他的数据却表现得不好。
这时候我们需要使用一些方法来评估我们的假设是否合理。
首先,我们需要把训练样本分为两部分,训练集合和测试集合
接着做如下步骤:
1.使用训练集合训练参数集合Θ 以及最小化Jtrain(Θ)
2.使用测试集合运算误差Jtrain(Θ)
测试集合误差计算
1.对于线性回归问题,按照如下公式
 2.对于分类问题,(非0即1)
第二个公式结果给出了分类错误的概率
2.对于分类问题,(非0即1)
第二个公式结果给出了分类错误的概率
模型选择以及训练/验证/测试集合
我们增加一个交叉验证集合
我们可以把学习样本分成三部分
1.训练样本 60%
2.交叉验证样本 20%
3.测试集合 20%
首先训练训练样本,然后将结果在交叉验证样本进行调试,最后使用测试样本进行测试。
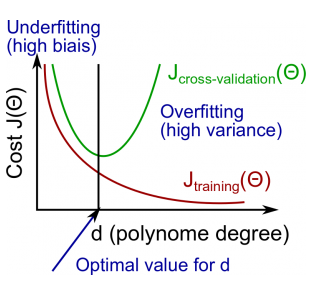
诊断偏差和方差
1.高偏差意味着我们的方案对训练样本的适应性不够
2.高方差意味着我们过度的适配了训练样本
这两种情况都会导致我们的解决方案对新加入的样本无法正确预测/适配
如何判断是否高偏差/高方差
高偏差, Jtrain(Θ) 和 JCV(Θ) 都很高而且相近
高方差, Jtrain(Θ) 很低 JCV(Θ) 很高
如下图
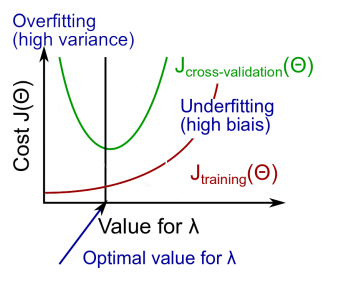
正则化参数λ对偏差和方差的影响
过大的λ会导致高偏差(过度正则化,不适配训练样本)
反之,过小的λ会导致高方差(过度适配训练样本)
如下图
学习曲线
即随着学习样本的增加,error的变化情况的曲线
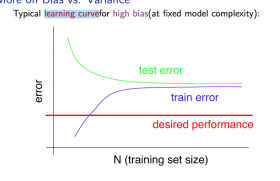
高偏差
在样本数量较小时,Jtrain(Θ)较小,JCV(Θ)较大
样本数量较多时,Jtrain(Θ)和JCV(Θ)都会较高且接近
当我们的算法高偏差时,增加样本数量不会对结果有明显的改善
高偏差
样本较小时与高偏差无异
样本较多时,JCV(Θ)减小,Jtrain(Θ)增加,JCV(Θ) > Jtrain(Θ),不会互相近似
高偏差时,增加测试样本可以提高算法学习精度
使用哪些手法优化机器学习效率
1.获取更多的训练样本
可以提高高方差情况下的效率
2.尝试使用更小规模的特称
可以提高高方差情况下的效率
3.尝试增加特征
可以提高高偏差情况下的效率
4.尝试使用多项式特征
可以提高高偏差情况下的效率
5.减小正则参数λ
可以提高高偏差情况下的效率
6.增加正则参数λ
可以提高高方差情况下的效率
神经网络问题的优化方法
1.参数较少的神经网络问题更易于不耦合训练样本,计算量也较少
2.拥有更多参数的神经网络问题容易过度耦合训练样本,但是计算量较大,可以用正则化来优化。
模型选择
主要有两方面的问题,选择多项式次数,选择哪些参数可以被留下,去掉哪些参数
主要有三个方式来解决这个问题
1.获取更多的数据(非常困难)
2.选择适合训练样本的模型(非常困难)
3.通过正则化来避免过度耦合