[W8]聚集
非监督学习:介绍
非监督学习和监督学习相反,是一种无标签学习。 换而言之,我们不知道y的具体分类。 非监督学习适用于: 1.市场分割 2.社交网络分析 3.组织电脑集群 4.天文数据分析K-Means算法
K-Means算法是最广泛应用的自动分类算法。 具体过程如下 1.随机在数据集合中初始化两个点,叫做聚类中心 2.将整个集合分为两个子集,一个是对于中心1较近的点,一个是对中心2较近的点 3.将划分好的集合中的点求出一个平均值,把聚类中心移到这个点 4.重复2和3过程优化算法
随机赋值
我们的算法有时会在局部最优解停留,我们需要做的是重复随机赋值几次,来确保取到全局最优解。选择聚类的数量
绘制代价曲线J和聚类数量k的图像,在代价曲线扁平化的那个点选择K的数量。 代价函数J的公式如下其中: c(i)表示x(i)当前属于的集群的序号 uk 表示集群中心k uc(i) 表示x(i)属于集群的集群中心
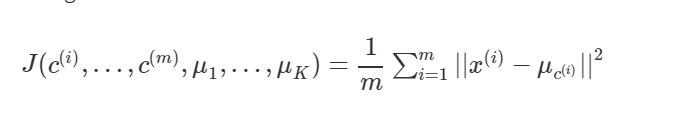
维度下降
有时候一个数据有多个维度的数据,但是我们为了一些需求,会想办法降低其维度,主要场景有两个 1.数据压缩 2.数据可视化PCA问题分析公式
最常见和常用的维度下降算法就是PCA(Principal Component Analysis)问题描述
这类问题是为了用一条线来同时描述多个特征,以及适配新的特征。 PCA的目的就是为了让每个点到这条线的投射距离的平均值最小。PCA并不是线性回归
在线性回归中,我们计算的是每个点的方差 在PCA中,我们计算的是每个点到线上的距离最小值PCA算法
1.给出训练样本集合 2.均值化训练集合
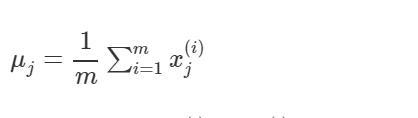
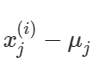
如何降低维度
首先计算协方差矩阵