[W9]异常检测
异常检测动机
当我们有新的数据样本的时候,我们希望通过一个模型p(x)以及一个门槛值ϵ来判定这个样本是否是异常的。
高斯分布
高斯分布是一种可以被描述为

的类钟型线。
具体公式是
其中几个参数的计算如下
普遍公式
只有公式部分不同,其余部分均与高斯分布相同
异常检测vs监督学习
何时使用异常检测
正样本较少,负样本多,正样本不够训练,且种类太多
何时使用监督学习
有大量的正负样本,我们有足够的正样本来训练,未来的正样本与现有的类似
推荐系统
推荐系统的目的是为了给用户推荐产品
这里有几个定义
nu 用户数量
nm 电影(产品)数量
r(i,j) = 1 表示用户j给电影i打了分了
y(i,j) 表示用户j给电影i打的分
基于内容的推荐
θ(j) 对于用户j的参数向量
x(i) 对于电影i的特征向量
预测用户j对电影i的评分公式
如何学习θ(j)?公式类似线性回归,如下
一次性学习全部的公式
协同筛选
如果我们不能获得准确的电影特征向量 x(i)
那么我们可以让用户告诉我们他们对每种类型有多少的喜爱,然后我们就能使用这些数据进行学习,公式如下
协同筛选算法步骤
首先是代价函数公式,如下
具体步骤:
1.初始化x(i)到x(nm)以及θ(1)到θ(nu)为很小的随机值,这一步是为了让每个x都不相同
2.最小化J(x(i),...,x(nm),θ(1),...,θ(nu))通过梯度下降或者高级算法均可
3.通过θTx预测用户评分

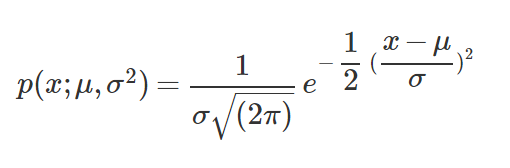
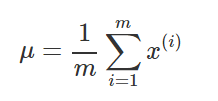
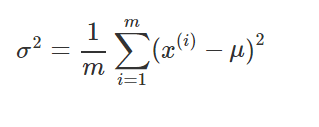
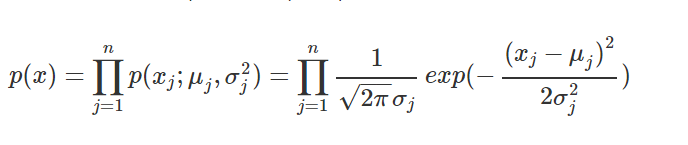
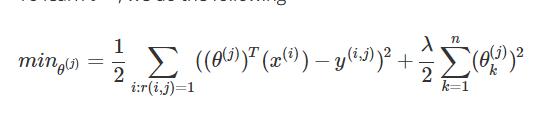
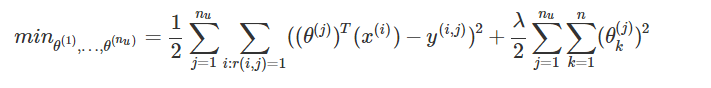
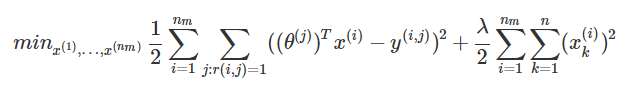
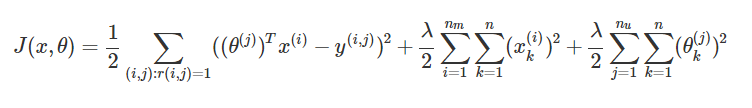

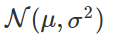{kind=link}
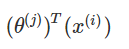{kind=link}